
You might have heard of reinforcement learning, lots of its magical stories from media and are curious about what it is. Reinforcement learning is about getting an agent learn to act given rewards. RL is inspired by behavioral psychology. The process is just like teaching a pet: you don’t tell it what to do, but you reward/punish it when it does the right/wrong thing. There are plenty of online tutorials which give you comprehensive ideas about reinforcement learning.
The Model
We can describe the RL process as follows. At each step, the agent receives observation and reward, and selects an action. The environment receives the action and emits another observation and reward. The goal is to maximize the total reward in long run.
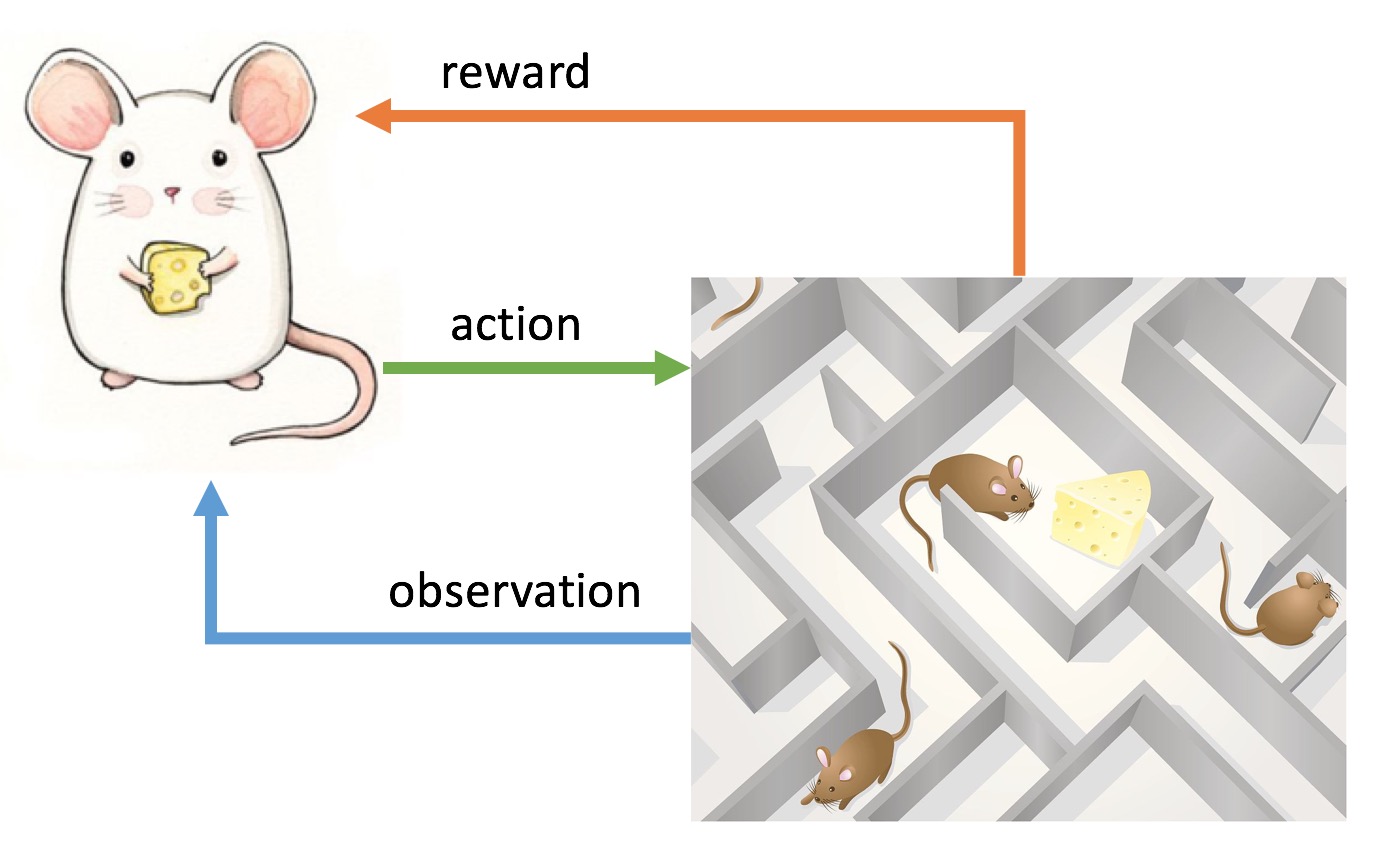
A policy is the agent’s behavior, it’s a mapping from state to action. Whereas the reward signal gives immediate score, a value function specifies a long-term desirability. Even a state yiels low rewards it might still have high value because its consequent states yield high rewards. Let’s illustrate the idea with a really simple example (with code).
A Simple Example: Training a Tic-Tac-Toe Player 1
Tic-Tac-Toe is a classic child’s game. Two players fullfill a 3x3 board in turn with Xs and Os until one wins by placing three marks in a row. The problem is to train an agent to play the game and maximize its chances of winning.
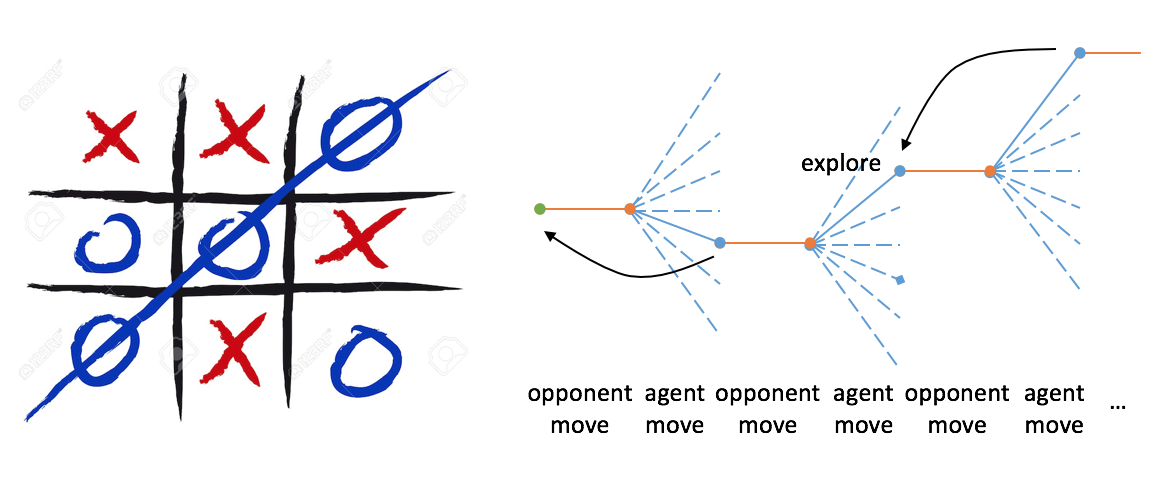
How do we apply RL to solve this problem? In this game, the states of the board are finite. We search a space of policies and greedily select the best one with high potential to beat the opponent. The chance of winning for each policy is estimated via value function. As the agent plays, value of a state V(s) is backed up to be closer to the value after the best move V(s’), which can be written as @@V(s)\leftarrow V(s)+\alpha[V(s’)-V(s)]@@. α is the step-size parameter and influences the learning rate. This update method is an example of temporal-difference learning. When the system’s random number is below a threshold ε, the agent ignores suggested move and takes a exploratory move.
Up til now, our agent is well-trained and ready to play with. Take a try! This example illustrates how a RL method works – there’s no supervisor or prior knowledge, the agent learns from interacting with environment with feedback. It’s also a remarkable feature that a RL agent can consider the delayed effects. It’s like it looks ahead for the best choice over a time span to achieve its goal in the future.
Discussions
- The agent prefers to take previous move with highest score to maximize reward. Also the agent has to try moves which it has not take before in order to improve policies, so the tradeoff between exploration and exploitation becomes a challenge since no one would guanrantee which is nicer to approach the goal.
- Besides the temporal-difference learning, some other approximation methods to estimate value function include Q-learning, SARSA, etc.
- RL can be used to solve complex problems whose states are huge or even infinite. We can estimate their value functions through neural network, combinations of features, etc.