Distributed Representation
In basic NLP tasks, each word is treated as discrete atomic unit. The word vector is filled with 0s and a single 1 meaning word apprearance. It’s easy to see that this one-hot representation is very sparse whose dimensionality is as large as the vocabulary size. It can be a big problem in real applications.
People come up with ideas of distributed word feature representations which describes different aspects of the word and each word is associated with a point in the vector space. The dimensionality of the representations is then much smaller. These dense vectors can be used to discover similarities between terms or as input of other NLP models.
Neural Network Language Model
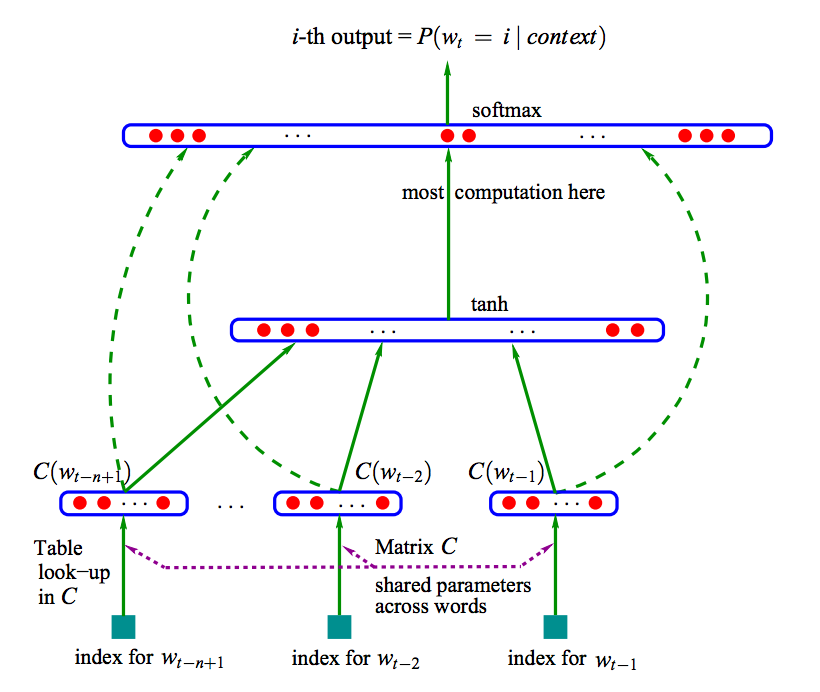
Bengio et al. proposed a framework to build language model with neural network. The basic idea can be summarized as below:
- Every word is associated with a feature vector.
- The joint probability of a word sequence is a function in terms of their feature vectors.
- Learn simultaneously the vectors and the parameters of the probability function.
The neural architecture looks like below, C(wt) is the feature vector:
Word2Vec Model
To learn from large amounts of text data, Mikolov et al. simplified the second step and introduced two efficient ways to learn high-quality word vectors. The CBOW architecture predicts the current word based on the context and the Skip-gram predicts surrounding words based on the current word. Both models can obtain quality vectors. These vectors are good at performing analogical reasoning tasks.
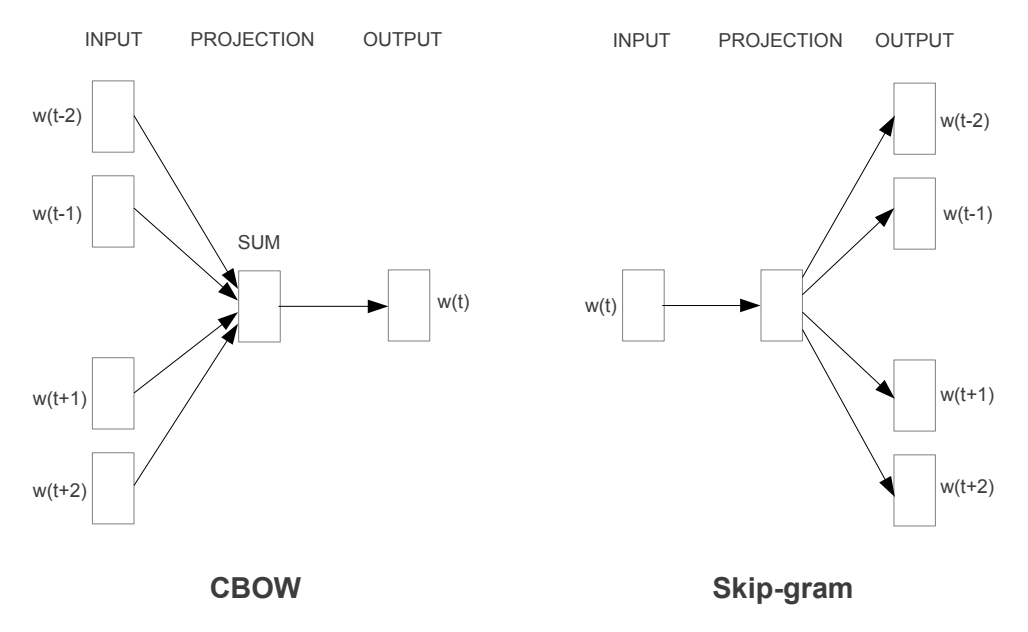
Later on, Mikolov et al. presented several extensions, including subsampling and negative sampling, to improve Skip-gram model in both quality and training speed. The word2vec models can be implemented using TensorFlow. It’s time to train your own word vectors!