
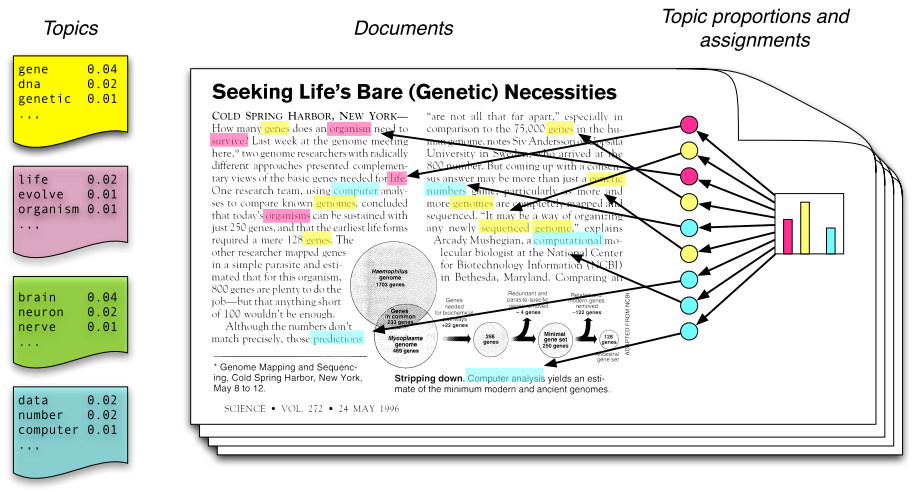
Topic modelling is a technique to automatically discover the hidden topics in each document. The basic idea is that words with similar meaning will occur in similar documents. A document is then modeled and described by topics coverages with word distributions. Latent Semantic Indexing (LSI) and Latent Dirichlet Allocation (LDA) are two common models. Practically the models perform similarly.
Knowing a set of documents d1, …, dm and vocabulary words w1, …, wn, we can construct a document-term matrix @@X \in \mathbb{R}^{m \times n}@@ where @@x_{ij}@@ describes the occurrence of word wj in document di and can be count, 0-1, or tf-idf.
We decompose X with @@X = U_t \Sigma V_t^T@@ with truncated SVD and get @@U_t@@ and @@V_t@@ representing topic weights in each document and word weights in each topics repectively. This method is the LSI.
Probabilistic LSI (pLSI) deals with probabilities instead. The Model is @@P(w|d) = P(d)\sum_t P(t|d)P(w|t)@@ and can be trained with EM algorithm. However, the model lacks knowledge to compute for new documents and the number of parameters grows as amount of documents increase.
LDA improves pLSI by imposing Dirichlet priors α and β to document-topic and topic-word distribution. LDA posits that the topics covered from both observed and unseen documents is drawn from a distribution Dirichlet(α) and words in a topic is drawn from another distribution Dirichlet(β). Now we only need to worry about α and β.
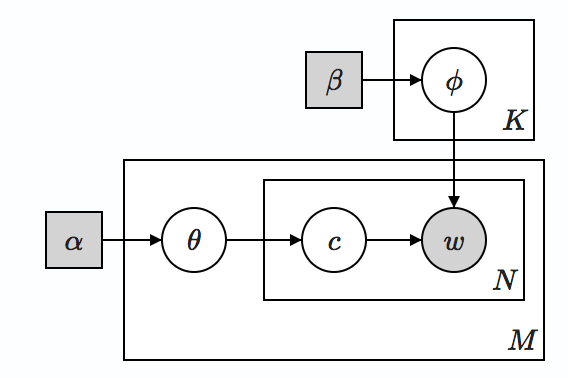
Graphical model representation of LDA
The pyscript that I used to implement topic models is here. I started with tokenizing and stemming each documents:
def preprocess(text):
stop = set(stopwords.words('english'))
stemmer = SnowballStemmer("english")
doc_tokenized = word_tokenize(text.decode('utf-8').lower())
doc_stop_stem = [word for word in doc_tokenized if re.search('[a-zA-Z]', word) and (word not in stop)]
return doc_stop_stem
The corpus is transformed in to either bag of words or tfidf vectors.
class topic_model():
def prepare_doc(self, fname):
...
self.dictionary = corpora.Dictionary(self.docs)
self.corpus = [self.dictionary.doc2bow(doc) for doc in self.docs]
self.tfidf = models.TfidfModel(self.corpus, id2word=self.dictionary)
self.corpus_tfidf = self.tfidf[self.corpus]
The process can be implemented with lda, lsi or log entropy model.
class topic_model():
def train(self, method='lda_tfidf', K=10):
if method == 'lda_tfidf':
logging.info("Training LDA model with tfidf.")
self.model = models.LdaModel(corpus=self.corpus_tfidf, num_topics=K, id2word=self.dictionary)
elif method == 'lda':
logging.info("Training LDA model.")
self.model = models.LdaModel(corpus=self.corpus, num_topics=K, id2word=self.dictionary)
elif method == 'lsi_tfidf':
logging.info("Training LSI model with tfidf.")
self.model = models.LsiModel(corpus=self.corpus_tfidf, num_topics=K, id2word=self.dictionary)
elif method == 'logentropy':
logging.info("Training log-entropy model.")
self.model = models.LogEntropyModel(corpus=self.corpus, id2word=self.dictionary)
else:
msg = "Unknown semantic method %s." % method
logging.error(msg)
raise NotImplementedError(msg)
The topic models are especially useful for calculating document similarities, finding related documents to a new query, and discovering semantic words.